
DID method to identify and resolve data schemas
Authors: Julian Voelkel, Majd Turfa, Jan-Paul Buchwald
TL;DR
In this article, we introduce a new DID method that is used to identify and resolve data schemas. By supporting different underlying decentralized storage mechanisms (currently public IPFS and Evan IPFS) and an optional declaration and validation of the schema type, it provides flexibility and allows future extensions. We believe the schema DID method can build the foundation for a decentralized schema registry with globally unique and immutable schema identifiers to be used across centralized and decentralized systems.
Introduction and motivation
Whenever pieces of data with a certain semantic meaning are exchanged between different parties, it is essential to agree on a format and structure of this data. This is usually achieved via schemas or schema definitions, and within the history of software development, many representations of such schemas evolved. Most common schemas in use are related to XML (XSD — XML Schema Definition), JSON (JSON Schema), DDL (SQL Databases), GraphQL (GraphQL Schema), but also to embedded protocols (Protobuf) or particular products and frameworks (Thrift, Avro).
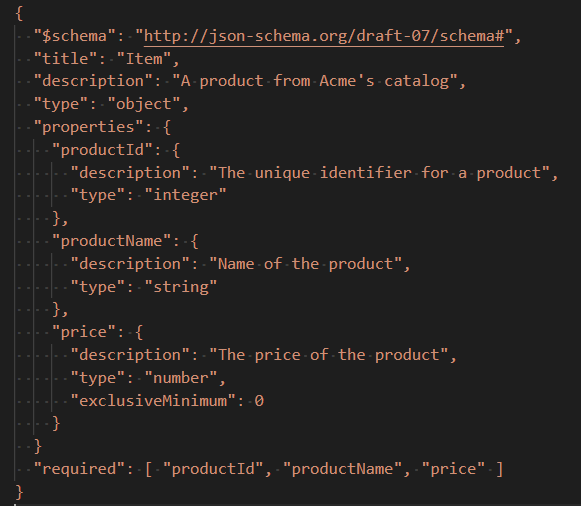
While a schema perfectly describes the structure of a piece of data and can be used to validate data, a further question is how to share those schemas between different parties or components using them. The obvious solution is a Schema Registry, meaning a repository to store and identify schemas. Today schema registries such as Confluent Schema Registry or Amazon EventBridge Schema Registry are used to store and address schemas in a particular namespace. This kind of schema registry is based on internal identification and central storage, which makes it dependent on a single party and narrows the usage scope immensely. So, we asked ourselves: how to share and reuse schema definitions across multiple systems or even globally?
The goal was to design a Decentralized Schema Registry based on a globally unique identifier allowing the use of immutable schemas which are accessible to the public or a set of relevant parties (depending on the chosen network).
Solution
Our solution for the previously stated challenge is a new DID method for identifying schemas, combined with a (preferably decentralized and immutable) storage mechanism. A schema DID should allow a globally unique resolution of the schema by providing a service endpoint to “get” or download the actual schema content. The DID format should be open to support multiple storage mechanisms or networks and provide a way to also expose the schema type.
The following gives some more explanation on the DID method and related software components we defined and implemented.
Schema Registry DID Method
The DID is comprised of multiple elements separated by colons (:):
- The general DID and method prefix did:schema
- The method-specific id consisting of:
1. A mandatory identifier for the storage network, chosen from a list of supported storage mechanisms and networks.
2. An optional identifier for the type or format of the schema, chosen from a list of supported types.
3. The mandatory schema-hash identifying the schema file in the given storage network, represented as a string.

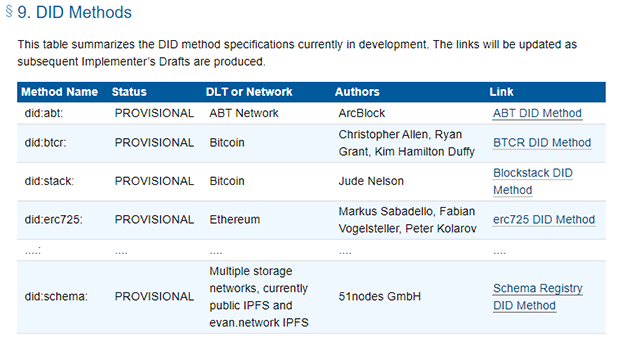
The full DID method specification can be found on GitHub. The schema DID method was also added to the official registry of DID methods in the W3C method registry.
Reference Library
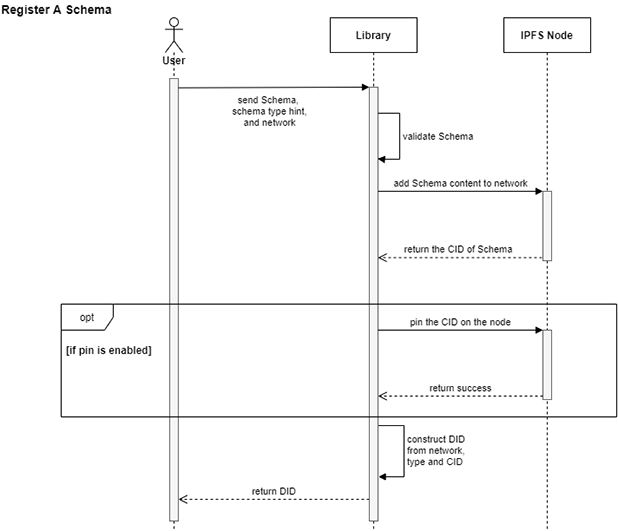
To make the DID method available for other developers, we implemented a Typescript based library that supports the registration and extraction of schemas on different distributed networks by the two functions registerSchema and getSchema.
- The registerSchema method is used to store the schema on one of the supported networks and it returns the DID of the schema. The schema type is a mandatory parameter, and the given schema content is validated to comply to the given type.
- The getSchema method gets a DID as Input and returns the schema that is stored behind the given DID. If the DID contains a schema type, the library validates the content and treats it as “not found” if it does not comply to the type.
For the first version of the library, the supported schema types are JSON-Schema and XSD, the supported storage networks are the public IPFS and Evan IPFS, which is a permissioned IPFS network provided by the evan.network. The library also provides a function to initialize the library by setting the configuration needed to connect to the required networks and other utility functions to handle the DID.
Data stored on IPFS gets usually removed after some time, and only pinned files are stored permanently on the node. Since each node in IPFS networks handles this individually and pinning may incur costs, the pin functionality can be enabled or disabled in the library configuration.
The library is published on npm as @51nodes/decentralized-schema-registry, and the source code is available on GitHub. Detailed instructions on how to use the library are described in the README file. The project also contains a simple JavaScript example.
DID Resolver
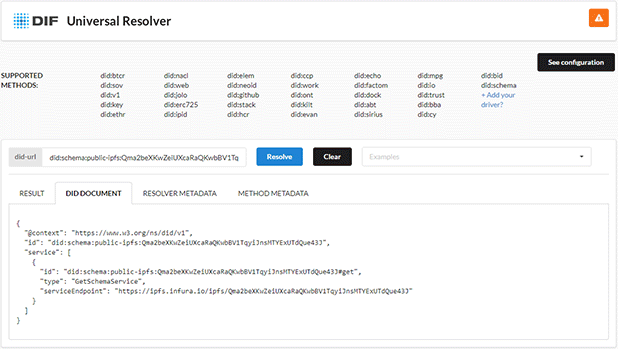
Using the provided library, we also implemented a DID resolver as a NestJS application. It provides a GET endpoint to get the DID document of a schema DID. An example of a returned DID document is

The DID document includes a service endpoint that points to a gateway that provides the underlying schema content. For the public IPFS this is currently an infura public gateway, and for the evan.network IPFS there is a central gateway from evan.network, both loading a single resource identified by hash from the respective IPFS network.
The NestJS Application is dockerized and the Docker image is published under 51nodes/schema-registry-did-resolver on Docker Hub. To build and run the driver locally, read the instructions with the provided source code which are published on GitHub.
The Docker image of the resolver was also added as a driver to the universal DID resolver, which aims to provide a central resolution service for all kinds of DID methods (currently over 30).
Independent from the universal resolver the driver provides a GET request to download the saved schema directly under the endpoint http://localhost:8080/1.0/identifiers/{did}/get
Benefits and Usage Scenarios
The main benefit of the schema DID is to allow a stable identifier and public registry for schema files or objects which could replace existing proprietary (siloed) schema registries or other schema storage solutions. Applications can use DIDs for referencing schemas stored in different locations and only need a standardized resolver (or use the universal resolver) to load the schema contents, allowing not only interoperability, but also much better reuse across systems and applications.
In particular, schema DIDs could be useful in the following scenarios:
Schema references and validation for distributed data storage
Schema DIDs can reference schemas for payload data in Blockchain or smart contract transactions. Further this approach enables the use of structured data in distributed file or data storages themselves, or could be used for schemas of Verifiable Credentials.
Cross-organization processes and communication
Cross-organizational interactions become even more important in times of decentralized systems. Collaboration is the key for enhancing processes. Schemas stored in a distributed manner would enable cross-organizational standardized data interfaces accessible to everyone. This could elevate the collaboration to another level.
Outlook and next steps
Firstly, we are happy to get feedback on the solution and would love to see first adoption in real-world applications. Of course, we plan to use the DID based decentralized schema registry in our own future projects as well. We also want to have a closer look on the relations and possible usage in linked data such as JSON-LD or IPLD and in composite or nested schemas.
For the schema DID framework itself, we are looking for other networks that could be used as alternative decentralized storage networks. Some of the interesting projects in this area that we will keep an eye on are FileCoin, BigChainDB, IPDB, Sia and arweave. We are looking as well to support other schema types like GraphQL-Schema for GraphQL which is getting more attention lately. Furthermore, implementing the library with other programming languages like Java and Rust would help to make the schema DID method available to a wider number of developers. For all those topics, we welcome interested open source developers to participate and help to grow the solution.
51nodes GmbH based in Stuttgart is a provider of crypto economy solutions.
51nodes supports companies and other organizations in realizing their Blockchain projects. 51nodes offers technical consulting and implementation with a focus on smart contracts, decentralized apps (DApps), integration of Blockchain with industry applications, and tokenization of assets.